HashSet Internals
HashSet
The HashSet is one of data structures in C#, allowing us to store unordered non-repeating elements.
It seems very boring as it doesn’t contain any index nor key to navigate through as we thought (which is not necessarily true, but we’ll learn about this later).
So, what’s the matter? Well, It gives us high-performance solution where uniqueness is a must.
Under the hood Hashset is using hash code due to the fact that every type implicitly inherits from the object class (structs also due to fact that they inherit from System.ValueType).
HashCode is created using built-in hash method that returns Int32. Number of possible combinations is finite, and It doesn’t ensures equality of two objects with the same hash.
Navigation through HashSet
Do you remember that I’ve told you, the fact that HashSet doesn’t contain index or key? If we look from the user perspective, this is true, but in reality this is the effect of encapsulation, that hides operations using hash code and buckets from the user.
You are thinking - What hashes have in common with buckets?
 In C#, HashSet using hash (which serves as a key), buckets, and entries. When You add a new element to the HashSet, a new hash is being calculated (our key), then We can get index of the specific bucket (remember, hash is the
In C#, HashSet using hash (which serves as a key), buckets, and entries. When You add a new element to the HashSet, a new hash is being calculated (our key), then We can get index of the specific bucket (remember, hash is the Int32), by hash % buckets.
Lastly, new entry is assigned at the first unassigned index of entries array, pointing at calculated bucket index.
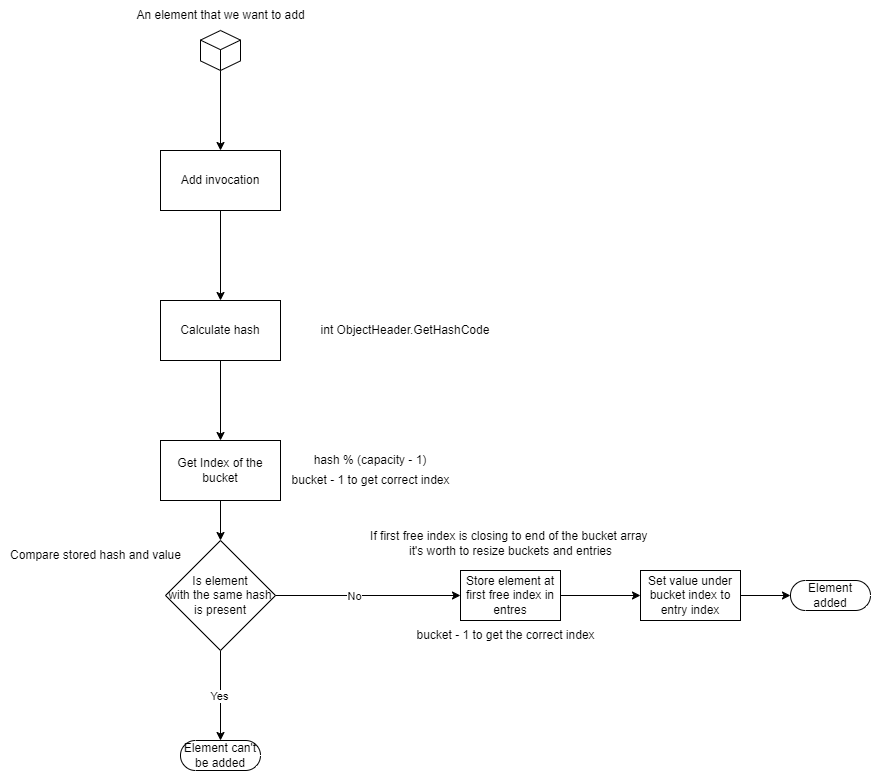 Similar behaviour exist when We check if element is already present. Calculate hash, get bucket index, check entry, if exist return true.
Similar behaviour exist when We check if element is already present. Calculate hash, get bucket index, check entry, if exist return true.
The core idea here is to lookup arrays to quickly retrieve the data. Steps for this will look like this:
1. Calculate hash (for C# object.GetHashCode(), or own solution)
2. Get bucket index (e.g hash % (capacity - 1), remember about subtraction of 1 from result of modulo to match indices)
3. In while loop get entry using bucket index, and check entry hash and value with incoming object, until index is negative
3.1. If not found set index to next entry element
Minimal HashSet implementation from scratch
After short description, now We should be able to do minimal implementation.
For this one I’ll go with struct, due to the fact that It can be allocated on stack, and we don’t need a swiss knife like in .NET source code here.
Secondly, We should support EqualityComparer to ensure a customizable equality checking for the incoming object.
Lastly, our input can be huge, so we can benefit from usage of an ArrayPool, but we must dispose rented arrays.
Let’s jump into coding:
public struct MinimalHashSet<T> : IDisposable
{
private const double LoadFactor = 0.75;
private Entry[] _entries;
private int[] _buckets;
private uint _capacity;
private int _startingIdx;
private int _threshold;
private readonly EqualityComparer<T> _comparer;
public MinimalHashSet()
{
_comparer = EqualityComparer<T>.Default;
}
public MinimalHashSet(int count)
{
_comparer = EqualityComparer<T>.Default;
}
public MinimalHashSet(T[] collection, EqualityComparer<T>? comparer = null)
{
if (collection == null)
{
throw new ArgumentNullException(nameof(collection));
}
_comparer = comparer ?? EqualityComparer<T>.Default;
//add logic here
}
The LoadFactor and _threshold will be explained later. _startingIdx represents the first not assigned index of an _entries array. The index is used for resizing purposes. Resizing is very important here as we don’t want to make copying operations on huge data sets very often.
It’s time to provide a Entry definition here, as it will be used heavily.
struct Entry
{
public uint Hash;
public T Value;
public int Next;
}
As We debated in second paragraph, we need to store a calculated hash, value and pointer to next bucket (if exist). Now we have everything to initialize variables required to have a empty hashset.
private void Construct(uint? count)
{
if (count == null || count < 16)
{
count = Math.Max(System.Numerics.BitOperations.RoundUpToPowerOf2(count ?? 0), 16);
}
_capacity = count.Value;
_threshold = (int)(count * LoadFactor);
_entries = ArrayPool<Entry>.Shared.Rent((int)count);
_buckets = ArrayPool<int>.Shared.Rent((int)count);
Array.Clear(_buckets);
}
When I saw RoundUpToPowerOf2 at ZLinq source code I was wandering why not use a Math.Pow, but after looking inside implementation it became obvious. The round up method uses a faster bit operation trick to calculate next highest power of two.
Rest of the code is an renting of arrays, clearing buckets and calculating the threshold for next resize. The threshold will be used to resize arrays when _startingIdx achieve the same value.
To this point I’ve talked about resizing few times. For the future Add method implementation It is crucial to get familiar with it beforehand.
private void Resize()
{
uint newSize = System.Numerics.BitOperations.RoundUpToPowerOf2((uint)_entries.Length * 2);
_capacity = newSize;
_threshold = (int)(newSize * LoadFactor);
Entry[] newEntries = ArrayPool<Entry>.Shared.Rent((int)newSize);
int[] newBuckets = ArrayPool<int>.Shared.Rent((int)newSize);
Array.Clear(newBuckets); //same as AsSpan().Clear()
_entries.AsSpan().CopyTo(newEntries);
for(int i =0; i < _startingIdx; i++)
{
ref Entry entry = ref newEntries[i];
if (entry.Next >= -1)
{
int bucketIdx = GetIndex(ref entry.Hash);
ref int bucket = ref newBuckets[bucketIdx];
entry.Next = bucket - 1;
bucket = i + 1;
}
}
ArrayPool<Entry>.Shared.Return(_entries, clearArray: RuntimeHelpers.IsReferenceOrContainsReferences<Entry>());
ArrayPool<int>.Shared.Return(_buckets);
_entries = newEntries;
_buckets = newBuckets;
}
private int GetIndex(ref uint hashCode)
{
return (int)(hashCode % (_capacity - 1));
}
The first lines shouldn’t be surprising. We just calculate a new size of arrays, set the threshold, and rent new ones, then copy existing data.
But when We copied the data into an new array with different size it means that our GetIndex will introduce discrepanncy between existing and calculated value from the same hash.
So, we have to recalculate every pointer to next bucket, if exist.
Rest of the code focuses on returning rented arrays and assigning new ones at the place of the old.
When We’ve got resizing, index calculation and initialization of our HashSet It’s time to focus on Add method.
private uint InternalGetHashCode(ref T item)
{
if (item == null)
{
return 0;
}
return (uint)(_comparer.GetHashCode(item) & uint.MaxValue);
}
public bool Add(T item)
{
if (_buckets == null)
{
Construct(0);
}
uint hashCode = InternalGetHashCode(ref item);
ref int bucket = ref _buckets[GetIndex(ref hashCode)];
int i = bucket - 1;
uint collisions = 0;
while (i >= 0)
{
ref Entry entry = ref _entries[i];
if (entry.Hash == hashCode && _comparer.Equals(entry.Value, item))
{
return false;
}
i = entry.Next;
collisions++;
if (collisions > _entries.Length)
{
throw new InvalidOperationException("Concurrent operations not supported.");
}
}
if (_startingIdx > _threshold)
{
Resize();
bucket = ref _buckets[GetIndex(ref hashCode)];
}
ref Entry newEntry = ref _entries[_startingIdx];
newEntry.Hash = hashCode;
newEntry.Value = item;
newEntry.Next = bucket - 1;
bucket = _startingIdx + 1;
_startingIdx++;
return true;
}
Let’s start from InternalGetHashCode.
Here we calculating hash using .NET build-in method and a bitwise logical and.
Speaking of Add things get more difficult.
As I mentioned in previous paragraph, we call for InternalGetHashCode then GetIndex to calculate hash and position incoming element in bucket. Number of bucket needs correct index (that’s why We subtracting here). Additionally, We initializing a collisions counter, like in the original implementation. When We’ve got a hash and bucket entry, We should perform lookup if element exist. To achieve this let’s create a while loop and iterate it until index i is non-negative. If we match hash with entry, and its values then we can’t add element to HashSet - it already exists, otherwise we assign next bucket pointer to our index i. Lastly we increment collision, and throw exception if collisions count is greater than existing entries.
We are at the point that we are sure about uniqueness of element. So, we have to check if _startingIdx of next element is closing to end of our rented arrays. If condition is true, then we use our Resize and recalculate bucket index, otherwise We just add an element.
Moving onwards to Contains method, it turned out that implementation will look like an mirror image, but without adding.
public bool Contains(T item)
{
if (_buckets == null)
{
return false;
}
uint hashCode = InternalGetHashCode(ref item);
ref int bucket = ref _buckets[GetIndex(ref hashCode)];
int i = bucket - 1;
uint collisions = 0;
while (i >= 0)
{
ref Entry entry = ref _entries[i];
if (entry.Hash == hashCode && _comparer.Equals(entry.Value, item))
{
return true;
}
i = entry.Next;
collisions++;
if (collisions > _entries.Length)
{
throw new InvalidOperationException("Concurrent operations not supported.");
}
}
return false;
}
To end this struct, we should gracefully return used resources. And remember to update our constructors with newly implemented methods.
public MinimalHashSet()
{
_comparer = EqualityComparer<T>.Default;
Construct(0);
}
public MinimalHashSet(int count)
{
_comparer = EqualityComparer<T>.Default;
Construct((uint)count);
}
public MinimalHashSet(T[] collection, EqualityComparer<T>? comparer = null)
{
if (collection == null)
{
throw new ArgumentNullException(nameof(collection));
}
_comparer = comparer ?? EqualityComparer<T>.Default;
Construct((uint)collection.Length);
for (int i = 0; i < collection.Length; i++)
{
Add(collection[i]);
}
}
public void Dispose()
{
if (_buckets != null)
{
ArrayPool<int>.Shared.Return(_buckets);
_buckets = null!;
}
if (_entries != null)
{
ArrayPool<Entry>.Shared.Return(_entries);
_entries = null!;
}
}
Whole struct should look like this.
public struct MinimalHashSet<T> : IDisposable
{
private const double LoadFactor = 0.75;
private Entry[] _entries;
private int[] _buckets;
private uint _capacity;
private int _startingIdx;
private int _threshold;
private readonly EqualityComparer<T> _comparer;
public MinimalHashSet()
{
_comparer = EqualityComparer<T>.Default;
Construct(0);
}
public MinimalHashSet(int count)
{
_comparer = EqualityComparer<T>.Default;
Construct((uint)count);
}
public MinimalHashSet(T[] collection, EqualityComparer<T>? comparer = null)
{
if (collection == null)
{
throw new ArgumentNullException(nameof(collection));
}
_comparer = comparer ?? EqualityComparer<T>.Default;
Construct((uint)collection.Length);
for (int i = 0; i < collection.Length; i++)
{
Add(collection[i]);
}
}
public bool Contains(T item)
{
if (_buckets == null)
{
return false;
}
uint hashCode = InternalGetHashCode(ref item);
ref int bucket = ref _buckets[GetIndex(ref hashCode)];
int i = bucket - 1;
uint collisions = 0;
while (i >= 0)
{
ref Entry entry = ref _entries[i];
if (entry.Hash == hashCode && _comparer.Equals(entry.Value, item))
{
return true;
}
i = entry.Next;
collisions++;
if (collisions > _entries.Length)
{
throw new InvalidOperationException("Concurrent operations not supported.");
}
}
return false;
}
public bool Add(T item)
{
if (_buckets == null)
{
Construct(0);
}
uint hashCode = InternalGetHashCode(ref item);
ref int bucket = ref _buckets[GetIndex(ref hashCode)];
int i = bucket - 1;
uint collisions = 0;
while (i >= 0)
{
ref Entry entry = ref _entries[i];
if (entry.Hash == hashCode && _comparer.Equals(entry.Value, item))
{
return false;
}
i = entry.Next;
collisions++;
if (collisions > _entries.Length)
{
throw new InvalidOperationException("Concurrent operations not supported.");
}
}
if (_startingIdx > _threshold)
{
Resize();
bucket = ref _buckets[GetIndex(ref hashCode)];
}
ref Entry newEntry = ref _entries[_startingIdx];
newEntry.Hash = hashCode;
newEntry.Value = item;
newEntry.Next = bucket - 1;
bucket = _startingIdx + 1;
_startingIdx++;
return true;
}
private void Resize()
{
uint newSize = System.Numerics.BitOperations.RoundUpToPowerOf2((uint)_entries.Length * 2);
_capacity = newSize;
_threshold = (int)(newSize * LoadFactor);
Entry[] newEntries = ArrayPool<Entry>.Shared.Rent((int)newSize);
int[] newBuckets = ArrayPool<int>.Shared.Rent((int)newSize);
Array.Clear(newBuckets); //same as AsSpan().Clear()
_entries.AsSpan().CopyTo(newEntries);
for(int i =0; i < _startingIdx; i++)
{
ref Entry entry = ref newEntries[i];
if (entry.Next >= -1)
{
int bucketIdx = GetIndex(ref entry.Hash);
ref int bucket = ref newBuckets[bucketIdx];
entry.Next = bucket - 1;
bucket = i + 1;
}
}
ArrayPool<Entry>.Shared.Return(_entries, clearArray: RuntimeHelpers.IsReferenceOrContainsReferences<Entry>());
ArrayPool<int>.Shared.Return(_buckets);
_entries = newEntries;
_buckets = newBuckets;
}
private void Construct(uint? count)
{
if (count == null || count < 16)
{
count = Math.Max(System.Numerics.BitOperations.RoundUpToPowerOf2(count ?? 0), 16);
}
_capacity = count.Value;
_threshold = (int)(count * LoadFactor);
_entries = ArrayPool<Entry>.Shared.Rent((int)count);
_buckets = ArrayPool<int>.Shared.Rent((int)count);
Array.Clear(_buckets);
}
private int GetIndex(ref uint hashCode)
{
return (int)(hashCode % (_capacity - 1));
}
private uint InternalGetHashCode(ref T item)
{
if (item == null)
{
return 0;
}
return (uint)(_comparer.GetHashCode(item) & uint.MaxValue);
}
struct Entry
{
public uint Hash;
public T Value;
public int Next;
}
public void Dispose()
{
if (_buckets != null)
{
ArrayPool<int>.Shared.Return(_buckets);
_buckets = null!;
}
if (_entries != null)
{
ArrayPool<Entry>.Shared.Return(_entries);
_entries = null!;
}
}
}
Benchmarks
Let’s see how does our implementation work against .NET original one.
Add method:
| Method | Mean | Error | StdDev | Median | Gen0 | Gen1 | Gen2 | Allocated |
|--------------- |---------:|---------:|---------:|---------:|----------:|----------:|----------:|----------:|
| AddToMyHashSet | 319.9 ms | 8.50 ms | 24.10 ms | 312.2 ms | 1000.0000 | 1000.0000 | 1000.0000 | 256 MB |
| AddToHashSet | 642.5 ms | 19.02 ms | 54.87 ms | 620.8 ms | 1000.0000 | 1000.0000 | 1000.0000 | 359.9 MB |
Contains method:
| Method | Mean | Error | StdDev | Median | Allocated |
|------------------------ |---------:|---------:|---------:|---------:|----------:|
| ContainsInMyHashSet | 304.8 ms | 6.93 ms | 19.65 ms | 300.1 ms | - |
| ContainsInHashSet | 306.1 ms | 6.07 ms | 14.77 ms | 301.2 ms | - |
| ContainsInMyHashSetMiss | 344.6 ms | 14.95 ms | 43.39 ms | 332.1 ms | - |
| ContainsInHashSetMiss | 343.9 ms | 12.65 ms | 36.91 ms | 331.8 ms | - |
Source code and sources
Sources not linked/barely linked above:
ZLinq HashSetSlim
Thomas Levesque blog